Phoebe: built for scale
Phoebe is a self-hostable variant warehouse for organizations whose genomic data is too valuable to sit idle. We provide an infrastructure layer that scales natively with your sample volume, allowing commercial labs, biobanks, and research teams to incrementally ingest data and run population-scale searches without bottlenecks.
Why does Phoebe exist?
Clinicogenomic collections across industry and academia have accumulated enormous potential as they have grown. These huge resources should be used by diagnostic and biobank companies to:
- Unlock new revenue streams from valuable data. Scientists and executives should be able to answer feasibility questions live on a call with life sciences collaborators, not by email the next day. Phoebe is also a perfect engine to power user-facing dashboards for cohort-building queries.
- Reclassify historical VUS at scale. Reapply updated interpretation logic across a complete collection without rerunning pipelines.
- Validate pipelines with confidence. Compare calls across versions against a stable queryable resource.
What Phoebe does:
Search live
Answer cohort, gene, variant, and annotation lookup questions in seconds. Broader scans fan out across local workers or cloud functions.
Keep ingest moving
Add new samples or annotations incrementally while the warehouse remains queryable. Phoebe merges and indexes them in the background.
Reanalyze on the fly
Store annotations independently from variant calls. New ClinVar releases or gnomAD updates do not require rewriting the underlying variant store.
Run anywhere
Deploy on public clouds or air-gapped on-prem infrastructure. Phoebe uses whatever compute you've got and requires no outbound network access.
Tradeoffs
Scalability and operational simplicity over millisecond latency.
A relational database can give you millisecond search latency for a demo with the 1000 Genomes Project, and will fall over completely as it scales to tens or hundreds of thousands of samples. Phoebe is designed to scale past millions of genomes on commodity infrastructure like object storage (e.g. AWS S3) and serverless (spot-compatible) compute (e.g. AWS Batch, AWS Lambda). Serving queries from object storage introduces a minimum latency of several hundred milliseconds, but makes your infrastructure team's life much easier. Phoebe runs significantly faster from SSDs, but for most organizations this isn't worth the trouble.
Excellence in core engine capabilities over a mediocre all-in-one solution.
Phoebe is not a clinical interpretation UI, trusted research environment (TRE), workflow orchestrator, or managed SaaS platform. It is best-in-class storage and retrieval infrastructure for the genomic data itself: the durable database layer between large variant collections and the people, systems, and analyses that need to use them.
Analytical performance over transactional latency.
Phoebe is not designed for transactional workloads, and works better when samples are ingested and processed in batches (e.g. daily), not one by one.
Architecture
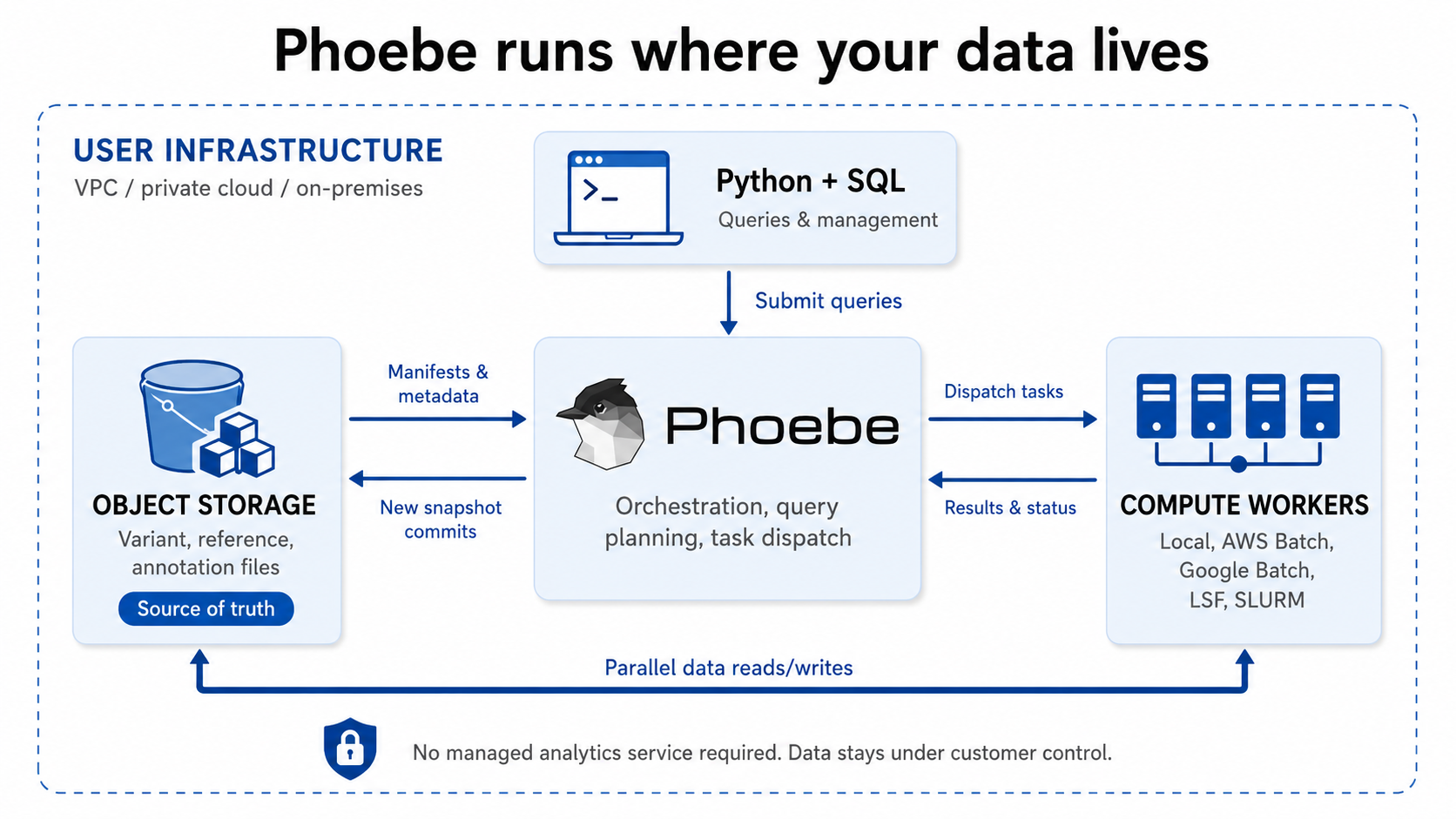
Phoebe maintains a custom table format inspired by log-structured merge trees and cloud-native data lakes on top of columnar Apache Vortex files. Phoebe builds efficient query plans that are run locally or in parallel leveraging Apache Arrow and DataFusion for in-memory execution and SQL query processing. Database snapshots are immutable and support time travel for audits, debugging, and reproducible reanalysis.
Phoebe is implemented primarily in Rust for performance and safety, and operated from Python.
Variants, genotypes, reference blocks, and annotations are stored independently so each can use the representation that fits the data, and so that each query touches only the relevant data. Annotation versions and superimposable layers can be updated and queried without rewriting variant calls.
Built for regulated environments.
Phoebe is licensed software deployed directly onto your cloud or physical infrastructure. Requiring no outbound network access during operation, Phoebe drops seamlessly into highly secure infrastructure, whether that's a firewalled cloud VPC or air-gapped servers.
We offer enterprise SLAs, regular update paths for new features, and hands-on partnership. Implementation, schema design, and support come directly from the engineering team that built the engine.